Build SRE Agent: Incident Response & ChatOps on EKS
Guide to building a Python based SRE Agent and ChatOps commands
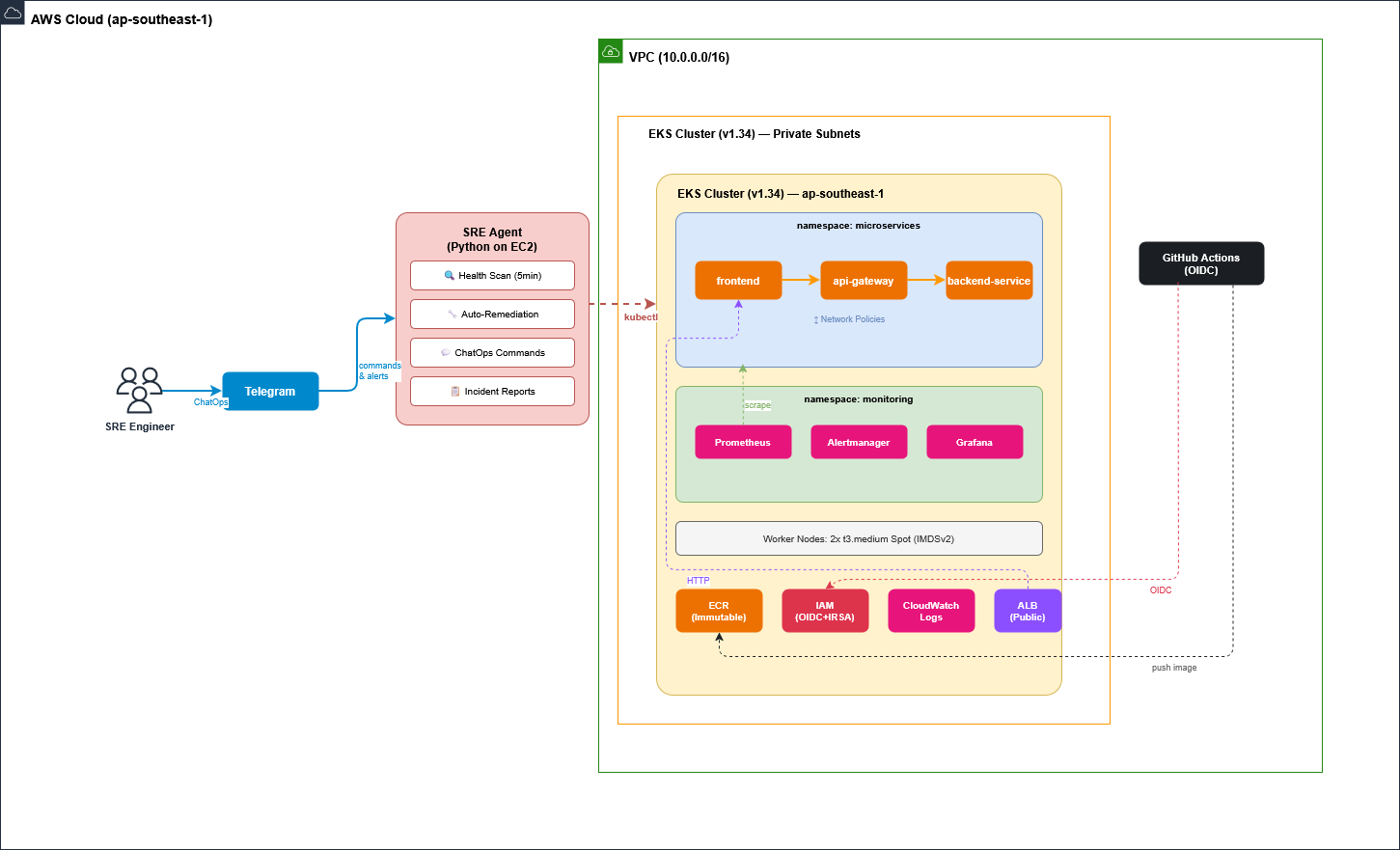
Repo: github.com/ahakimx/eks-microservices-lab
A step-by-step guide to building a Python-based SRE Agent that can scan cluster health, auto-remediate issues, and handle ChatOps commands, running on Amazon EKS.
Prerequisites
- AWS CLI configured + IAM user/role with EKS access
- Terraform >= 1.5
- kubectl
- Docker
- Python 3.11+
- GitHub repo with Actions enabled
Step 1: Provision EKS Cluster with Terraform
1.1 VPC + EKS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# terraform/eks.tf
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.5"
name = "eks-lab-vpc"
cidr = "10.0.0.0/16"
azs = ["ap-southeast-1a", "ap-southeast-1b", "ap-southeast-1c"]
private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = true
single_nat_gateway = true
enable_dns_hostnames = true
}
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.8"
cluster_name = "eks-lab"
cluster_version = "1.34"
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
cluster_endpoint_public_access = true
cluster_endpoint_private_access = true
# Logging for audit trail
cluster_enabled_log_types = ["api", "audit", "authenticator", "controllerManager", "scheduler"]
# IRSA enabled
enable_irsa = true
eks_managed_node_groups = {
spot_nodes = {
instance_types = ["t3.medium"]
capacity_type = "SPOT"
min_size = 1
max_size = 3
desired_size = 2
# IMDSv2 required — prevent SSRF credential theft
metadata_options = {
http_endpoint = "enabled"
http_tokens = "required"
http_put_response_hop_limit = 1
}
}
}
}
1.2 ECR with Immutable Tags
1
2
3
4
5
6
7
8
9
10
resource "aws_ecr_repository" "services" {
for_each = toset(["frontend", "api-gateway", "backend-service"])
name = "eks-lab/${each.key}"
image_tag_mutability = "IMMUTABLE" # Prevent tag overwrite attacks
image_scanning_configuration {
scan_on_push = true # Auto vulnerability scan
}
}
1.3 IAM Permission Policy
The IAM user/role running Terraform needs the following policy:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EKSManagement",
"Effect": "Allow",
"Action": [
"eks:*"
],
"Resource": "*"
},
{
"Sid": "IAMRolesForEKS",
"Effect": "Allow",
"Action": [
"iam:CreateRole",
"iam:DeleteRole",
"iam:AttachRolePolicy",
"iam:DetachRolePolicy",
"iam:PutRolePolicy",
"iam:DeleteRolePolicy",
"iam:GetRole",
"iam:GetRolePolicy",
"iam:ListRolePolicies",
"iam:ListAttachedRolePolicies",
"iam:TagRole",
"iam:UntagRole",
"iam:CreateInstanceProfile",
"iam:DeleteInstanceProfile",
"iam:AddRoleToInstanceProfile",
"iam:RemoveRoleFromInstanceProfile",
"iam:GetInstanceProfile",
"iam:ListInstanceProfilesForRole",
"iam:CreateOpenIDConnectProvider",
"iam:DeleteOpenIDConnectProvider",
"iam:GetOpenIDConnectProvider",
"iam:TagOpenIDConnectProvider",
"iam:ListOpenIDConnectProviders",
"iam:CreatePolicy",
"iam:DeletePolicy",
"iam:GetPolicy",
"iam:GetPolicyVersion",
"iam:ListPolicyVersions",
"iam:CreatePolicyVersion",
"iam:DeletePolicyVersion",
"iam:TagPolicy",
"iam:UntagPolicy"
],
"Resource": "*"
},
{
"Sid": "PassRoleEKSOnly",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<account>:role/eks-*",
"Condition": {
"StringEquals": {
"iam:PassedToService": [
"eks.amazonaws.com",
"ec2.amazonaws.com"
]
}
}
},
{
"Sid": "CreateSLREKSOnly",
"Effect": "Allow",
"Action": "iam:CreateServiceLinkedRole",
"Resource": "*",
"Condition": {
"StringEquals": {
"iam:AWSServiceName": "eks.amazonaws.com"
}
}
},
{
"Sid": "VPCNetworking",
"Effect": "Allow",
"Action": [
"ec2:*"
],
"Resource": "*"
},
{
"Sid": "ECRManagement",
"Effect": "Allow",
"Action": [
"ecr:*"
],
"Resource": "*"
},
{
"Sid": "CloudWatchLogs",
"Effect": "Allow",
"Action": [
"cloudwatch:*",
"logs:*"
],
"Resource": "*"
},
{
"Sid": "S3TerraformState",
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::terraform-state-*",
"arn:aws:s3:::terraform-state-*/*"
]
},
{
"Sid": "DynamoDBLock",
"Effect": "Allow",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:*:*:table/terraform-lock*"
}
]
}
Note: For production, scope down
ec2:*andecr:*to the specific actions needed. The policy above is sufficient for lab/POC purposes.
1.4 GitHub Actions OIDC Role
So that CI/CD doesn’t need to store AWS credentials:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::<account>:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
},
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:<github-username>/eks-microservices-lab:*"
}
}
}
]
}
This role needs the following permissions: ECR push, EKS describe/update-kubeconfig, and kubectl access.
1.5 Deploy
1
2
3
4
5
6
7
cd terraform
terraform init
terraform plan
terraform apply
# Update kubeconfig
aws eks update-kubeconfig --name eks-lab --region ap-southeast-1
Step 2: Deploy Microservices
2.1 Kubernetes Manifests
Key security features in the manifests:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# k8s/microservices.yaml (excerpt)
spec:
template:
spec:
containers:
- name: backend-service
image: <account>.dkr.ecr.ap-southeast-1.amazonaws.com/eks-lab/backend-service:v1.0.0
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
livenessProbe:
httpGet:
path: /health
port: 3000
readinessProbe:
httpGet:
path: /health
port: 3000
# Non-root container
securityContext:
runAsNonRoot: true
runAsUser: 1001
2.2 Network Policies
Traffic flow is restricted: only frontend → api-gateway → backend-service.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-gateway-to-backend
namespace: microservices
spec:
podSelector:
matchLabels:
app: backend-service
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: api-gateway
ports:
- port: 3000
2.3 Deploy
1
2
3
4
5
6
7
8
# Build & push (all services)
for svc in frontend api-gateway backend-service; do
docker build -t <account>.dkr.ecr.ap-southeast-1.amazonaws.com/eks-lab/${svc}:v1.0.0 microservices/${svc}/
docker push <account>.dkr.ecr.ap-southeast-1.amazonaws.com/eks-lab/${svc}:v1.0.0
done
# Apply manifests
kubectl apply -f k8s/microservices.yaml
Step 3: Setup Monitoring (Prometheus + Grafana)
Deployed via Helm in Terraform:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
resource "helm_release" "prometheus" {
name = "prometheus"
repository = "https://prometheus-community.github.io/helm-charts"
chart = "kube-prometheus-stack"
namespace = "monitoring"
version = "57.0.1"
values = [yamlencode({
grafana = {
enabled = true
service = { type = "LoadBalancer" }
}
prometheus = {
prometheusSpec = {
retention = "7d"
}
}
})]
}
All microservices already have annotations for Prometheus scraping:
1
2
3
4
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "3000"
prometheus.io/path: "/metrics"
Step 4: CI/CD with GitHub Actions + OIDC
4.1 OIDC Provider (no long-lived credentials)
GitHub Actions authenticates to AWS via OIDC — no need to store AWS keys as secrets.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# .github/workflows/deploy.yml
name: Deploy to EKS
on:
push:
branches: [main]
permissions:
id-token: write
contents: read
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Configure AWS credentials (OIDC)
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: arn:aws:iam::<account>:role/github-actions-eks-deploy
aws-region: ap-southeast-1
- name: Login to ECR
uses: aws-actions/amazon-ecr-login@v2
- name: Build & Push
run: |
docker build -t $ECR_URL/backend-service:$ .
docker push $ECR_URL/backend-service:$
- name: Deploy to EKS
run: |
aws eks update-kubeconfig --name eks-lab --region ap-southeast-1
kubectl set image deployment/backend-service \
backend-service=$ECR_URL/backend-service:$ \
-n microservices
Step 5: Build SRE Agent
This is the main part. The SRE Agent is a Python script with two modes:
- Proactive (Scan Mode) — scans cluster health, auto-remediates
- Reactive (ChatOps Mode) — receives commands, executes them, returns results
5.1 Core: Cluster Health Scanner
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# agents/sre-agent/sre_agent.py
def scan_cluster_health() -> dict:
"""Full cluster health scan."""
findings = []
# 1. Node health — check Ready condition + resource pressure
rc, out = kubectl("get nodes -o json")
if rc == 0:
nodes = json.loads(out)
for node in nodes.get("items", []):
name = node["metadata"]["name"]
conditions = {c["type"]: c["status"] for c in node["status"].get("conditions", [])}
if conditions.get("Ready") != "True":
findings.append({
"severity": "critical",
"type": "node_not_ready",
"resource": name,
"message": f"Node {name} is NOT Ready",
"auto_remediate": False
})
# 2. Pod health — CrashLoopBackOff, ImagePullBackOff, Pending
rc, out = kubectl("get pods -A -o json")
if rc == 0:
pods = json.loads(out)
for pod in pods.get("items", []):
# ... detect crash loops, image pull errors, stuck pending pods
pass
# 3. Deployment health — available vs desired replicas
# 4. Service endpoints — detect services with no backends
return {
"timestamp": datetime.now(timezone.utc).isoformat(),
"findings": findings,
"total": len(findings),
"critical": len([f for f in findings if f["severity"] == "critical"]),
}
5.2 Auto-Remediation
The agent can auto-fix certain issues (with safety guards):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def auto_remediate(findings: list) -> list:
"""Auto-remediate findings where possible."""
actions_taken = []
for f in findings:
if not f.get("auto_remediate"):
continue
if f["action"] == "restart_pod":
ns, pod = f["resource"].split("/")
# Safety: only restart if < 10 restarts (avoid infinite loop)
if f.get("restart_count", 0) < 10:
rc, out = kubectl(f"delete pod {pod} -n {ns}")
actions_taken.append({
"finding": f["message"],
"action": f"Deleted pod {pod} (will be recreated by deployment)",
"success": rc == 0,
})
return actions_taken
5.3 ChatOps Commands
The agent can handle interactive commands:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
COMMANDS = {
"status": "Show cluster/service status",
"pods": "List pods (optional: namespace)",
"logs": "Get pod logs (service name, optional: lines)",
"restart": "Restart a deployment",
"scale": "Scale a deployment",
"health": "Full health scan",
"top": "Resource usage (nodes/pods)",
"events": "Recent cluster events",
"rollback": "Rollback a deployment",
"help": "Show available commands",
}
def handle_command(command: str) -> str:
"""Parse and execute a ChatOps command."""
parts = command.strip().lower().split()
cmd = parts[0]
args = parts[1:]
if cmd == "status":
return cmd_status(args)
elif cmd == "restart":
return cmd_restart(args)
elif cmd == "scale":
return cmd_scale(args)
# ... etc
5.4 Usage
1
2
3
4
5
6
7
8
9
10
# Proactive scan mode (e.g., via cron/scheduled job)
python sre_agent.py
# ChatOps mode (handle specific command)
python sre_agent.py status
python sre_agent.py pods microservices
python sre_agent.py restart backend-service
python sre_agent.py scale frontend 3
python sre_agent.py health
python sre_agent.py rollback api-gateway
Step 6: IRSA for SRE Agent (Least Privilege)
If the agent needs AWS API access (e.g., describe instances, read CloudWatch), use IRSA:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# IAM role for SRE Agent pod
module "sre_agent_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
role_name = "sre-agent-role"
oidc_providers = {
main = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["microservices:sre-agent"]
}
}
role_policy_arns = {
readonly = "arn:aws:iam::aws:policy/ReadOnlyAccess"
}
}
1
2
3
4
5
6
7
8
# K8s ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: sre-agent
namespace: microservices
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::<account>:role/sre-agent-role
Step 7: Run the Agent as a CronJob
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion: batch/v1
kind: CronJob
metadata:
name: sre-agent-scan
namespace: microservices
spec:
schedule: "*/5 * * * *" # Every 5 minutes
jobTemplate:
spec:
template:
spec:
serviceAccountName: sre-agent
containers:
- name: sre-agent
image: <account>.dkr.ecr.ap-southeast-1.amazonaws.com/eks-lab/sre-agent:v1.0.0
command: ["python", "sre_agent.py"]
restartPolicy: OnFailure
Security Highlights
| Layer | Implementation |
|---|---|
| OIDC | GitHub Actions → AWS without long-lived credentials |
| IRSA | Pod-level IAM, not shared node credentials |
| IMDSv2 | Prevents SSRF credential theft on worker nodes |
| Immutable Tags | ECR image tags cannot be overwritten |
| Network Policies | Pod-to-pod traffic restricted (frontend→gateway→backend) |
| Non-root | All containers run as UID 1001 |
| ECR Scan | Auto vulnerability scan on push |
| Encryption | EBS encrypted, EKS secrets encrypted at rest |
| Auto-remediation guard | Max restart count check, prevents infinite loops |
Sample Output
Scan Mode (All Clear)
✅ SRE Agent Scan — All Clear
Cluster healthy. No issues detected.
Scan Mode (Issues Found)
🚨 SRE Agent Scan — 2 issue(s)
⏰ 2026-05-25T09:30:00+00:00
🔴 Critical: 1 | 🟠 High: 1 | 🟡 Warning: 0
🔴 [crash_loop] Pod backend-service-abc123 in microservices is CrashLoopBackOff (restarts: 4)
🟠 [deployment_degraded] Deployment backend-service in microservices: 1/2 replicas available
Auto-remediation actions:
✅ Deleted pod backend-service-abc123 (will be recreated by deployment)
ChatOps: status
📊 Cluster Status
🖥 Nodes: 2/2 ✅
📦 Pods: 12/12 ✅
⚙️ Services:
🟢 frontend 2/2
🟢 api-gateway 2/2
🟢 backend-service 2/2
Next Steps
- Slack/Discord integration — send alerts and receive commands via webhook
- PagerDuty integration — escalate critical findings
- Runbook automation — expand auto-remediation rules
- ML-based anomaly detection — predict issues before they happen
- Multi-cluster support — scan multiple EKS clusters
Conclusion
With this setup, you have:
- EKS cluster that is production-grade (Spot nodes, private subnets, encrypted)
- Microservices with proper health checks, resource limits, and network isolation
- Monitoring via Prometheus + Grafana
- CI/CD that is secure (OIDC, no stored credentials)
- SRE Agent that can proactively detect issues, safely auto-fix them, and respond to ChatOps commands
Total cost for this lab: ~$3-5/day (Spot instances + NAT Gateway). Suitable for learning and POC before scaling to production.
Built with ☕ by Abdul Hakim